Training AI Agents Inside Minecraft with Deep Q-Networks
How I built SpigotPlex RL, a system that bridges Java Spigot plugins with PyTorch to train reinforcement learning agents in Minecraft.
- Machine Learning
- PyTorch
- Java
- Reinforcement Learning
By Jenn Barosa
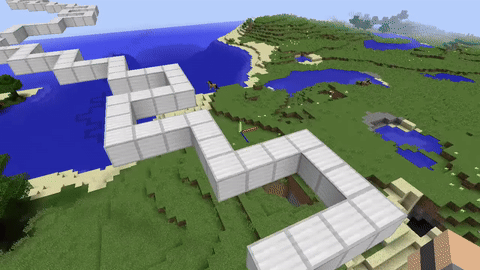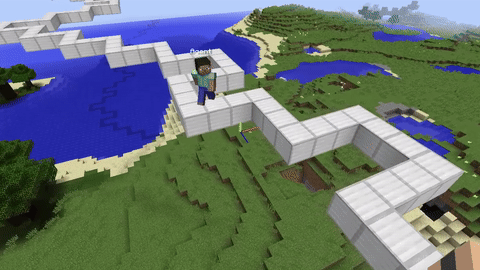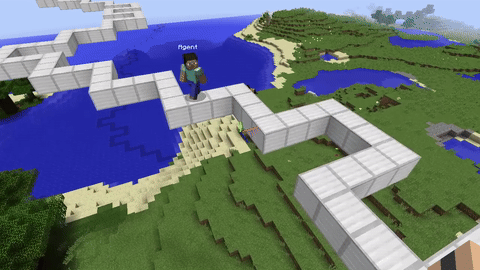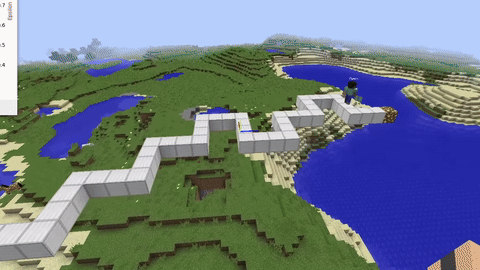
I wanted to train RL agents in something more complex than CartPole or Atari. Minecraft has 3D physics, partial observability, and you can build arbitrary environments with the in-game tools. It also has a huge modding ecosystem through Spigot, which made the integration side easier.
Bridging Java and Python
Minecraft servers run on Java. ML happens in Python. These two need to talk to each other fast enough for real-time training.
SpigotPlex RL runs as a Spigot plugin on a Minecraft 1.8.8 server. The plugin spawns and controls NPC entities, and it embeds a Javalin HTTP/WebSocket server on port 8755 with three endpoints:
- /state returns the current observation (NPC position, nearby blocks, entities in range, etc.) - /step takes an action, ticks the NPC forward, and returns the reward, next state, and a done flag - /reset puts the environment back to its starting conditions
On the Python side, I wrapped these HTTP calls in an OpenAI Gym environment class. So the training code looks like any standard Gym loop. The agent uses a DQN implemented in PyTorch with experience replay (100k transition buffer) and a target network that syncs every 1000 steps.
The Training Environments
I built three environments with different difficulty levels:
Beam Walking is a narrow bridge of blocks over a void. The agent gets +1 for each block it crosses and -10 for falling. It converges in about 5000 episodes and mostly just teaches the agent to go straight.
Parkour Course has platforms at different heights and distances. The agent has to learn jump timing, which is tricky because the window for a successful jump is only a few ticks. Reward is sparse here and it's sensitive to hyperparameter tuning. This one took a lot of runs to get working.
Landmark Navigation is an open area with distinct structures. The agent has to find a target location using spatial cues. This tests longer planning horizons.
Observation Representation Matters
The biggest takeaway was how much the observation format affects learning. For beam walking, raw XYZ coordinates work fine. But for landmark navigation, the agent couldn't converge on raw coordinates alone. Adding relative direction vectors to nearby blocks (basically giving it a sense of "the big tower is to my left") made it actually learn.
PS4 Controller
I wired up PS4 controller input for manual NPC control. This was useful in two ways: collecting demonstration trajectories for pretraining, and just getting a physical feel for what the controls are like so I could sanity-check the agent's behavior. Watching an agent through logs is one thing, but actually controlling the NPC yourself gives you better intuition for what's hard and what's easy.
Minecraft as an RL Platform
Minecraft is good for this because you can procedurally generate new environment layouts trivially, which prevents the agent from memorizing specific maps. The physics are deterministic for a given server tick, which makes debugging reproducible. And building new test environments is fast since you can just place blocks in creative mode.